<!doctype html>
[Java & DataBase] JDBC, JPA, Mybatis 차이점
스프링이나 이클립스를 통한 자바 개발을 진행하는 개발자라면 데이터베이스와 연동하는 과정을 개발해 본 경험이 있을 것입니다.
그중 관계형 데이터베이스(RDBMS)를 이용할 때 JDBC, JPA, Mybatis를 이용해 볼 수 있는데 구체적으로 어떠한 차이점이 있는지 궁금증이 생겨 개념 정리 및 학습을 진행하기 위해 한번 정리해볼까 합니다.
순서는 제가 학습했던 순서인 JDBC -> Mybatis -> JPA 순으로 설명하겠습니다
1. JDBC(Java Database Connectivity)
JDBC는 말 그대로 자바 프로그램이 데이터베이스와 연결할 수 있는 기능을 제공하는 프로그래밍 인터페이스입니다.
이러한 JDBC를 이용하기 위해서는 java.sql.Driver, java.sql.Connection, java.sql.Statement, ResultSet, PreparedStatement, CallableStatement 등을 이용 볼 수 있습니다. 실제 개발을 진행할 때는 import java.sql.*; 로 한 번에 가져와서 구현했습니다.
간단한 순서는 다음과 같습니다.
- Driver Load
- Connector Object Create -> Connection
- Statement Object Create
- Return Value Save Result Set Object
- Close
import java.sql.*;
public class ConnectDB{
public static void main(String[] args)
{
try{
//Connection Object Create
Connection conn = null;
//Connection
String url = "jdbc:mysql://localhost/DB_Name";
conn = DriverManager.getConnection(url, "DB_user", "DB_user_password");
System.out.println("연결 성공");
}
catch(ClassNotFoundException e) // Error Case 1
{
System.out.println("Driver Loading Fail");
}
catch(SQLException e) // Error Case 2
{
System.out.println("Error : " + e);
}
finally
{
try
{
if(conn != null && !conn.isClosed())
{
conn.close();
}
}
catch(SQLException e) // Error Case 3
{
e.printStackTrace();
}
}
}
}
이러한 불편은 점차 jdbc의 역사가 발전해나가며 SQL Mapper와 ORM을 이용할 경우 코드상 활용하는 방식이 간결해졌습니다
추가로 jdbc를 이용할 때 Driver는 DataBase회사별 다르기 때문에 "com.mysql.jdbc.Driver" 와 같이 직접 찾아서 입력해야 합니다.
쿼리를 요청하는 코드를 확인해보겠습니다.
import java.sql.*;
public class SelectCase
{
public static void main(String[] args)
{
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try{
// 1. Drvier Load
Class.forName("com.mysql.jdbc.Driver");
// 2. Connection
String url = "jdbc:mysql://localhost/DB_Name";
conn = DriverManager.getConnection(url, "DB_User", "DB_Password");
// 3. Statement Object Create
stmt = conn.createStatement();
// 4. Write Query
// 1) Select 할 때 * 로 모든 칼럼을 가져오기보단 특정 컬럼을 가져오는것이 좋다.
// 2) 원하는 결과는 쿼리로써 정리하고 후작업은 권장되지않음
// 3) 쿼리를 한 줄로 쓰기 어려운 경우 들여쓰기를 사용해도 되지만 띄어쓰기에 유의해야한다.
String sql = "SELECT name, owner, data_format(birth, '%Y년%m월%d일' date FROM table)";
// 5. Execute Query
rs = stmt.executeQuery(sql);
// 6. 실행결과 출력하기
while(rs.next())
{
//Record colunm은 1부터 시작하며 DataType에 맞게 getInt, getString등을 이용
String name = rs.getString(1);
String owner = rs.getString(2);
String date = rs.getString(3);
System.out.println(name + " " + owner + " " + date);
}
}
catch( ClassNotFoundException e){
System.out.println("드라이버 로딩 실패");
}
catch( SQLException e){
System.out.println("에러 " + e);
}
finally // Close Phase
{
try
{
if( conn != null && !conn.isClosed())
{
conn.close();
}
if( stmt != null && !stmt.isClosed())
{
stmt.close();
}
if( rs != null && !rs.isClosed())
{
rs.close();
}
}
catch( SQLException e)
{
e.printStackTrace();
}
}
}
물론 간결하다고 항상 좋은 것은 아니고 장, 단점이 존재합니다
위 코드는 MySQL 일 경우의 과정이고 이 JDBC 역시 Java에서 제공하는 API이기에 개발자 입장에서는 데이터베이스마다 사용 쿼리를 각 DB마다 작성해주어야 합니다(DB의존적인 쿼리문).
또한 연결, 연결 해제 등의 과정의 코드를 반복적으로 작성해야 하기에 코드가 많이 길어집니다.
이 방식도 역시나 기존 애플리케이션의 디비 연동 과정 보다도 간소화되었지만 여기서 끝이 아닌 새로운 2가지 기술이 또 등장합니다.
SQL Mapper , ORM
SQL Mapper
SQL Mapper의 대표적인 기술로는 아래에서 설명할 MyBatis가 있으며 쿼리문을 파일로 관리할 수 있다는 점에서 장점이 있습니다.
또 위 JDBC의 단점인 반복적인 코드를 줄이고 응답 결과 자체를 객체로 반환합니다.
ORM(Object-Relational Mapping)
ORM은 SQL문을 작성하지 않아도 동적으로 생성해주며 DB마다 다르게 사용하는 SQL도 동일하게 작성 가능합니다.
단점으로는 러닝 커브가 존재하고, SQL 작성이 없지만 테스트 과정이나 기타 여러 상황을 고려해 개발자는 알아야 합니다.
자세한 내용은 밑에 3. JPA에서 더 설명하겠습니다
2. Mybatis
- Mybatis는 Persistence framework입니다.
- MyBatis는 위 사용했던 JDBC를 통해 데이터베이스에 액세스 하는 작업을 캡슐화하고 일반 SQL 쿼리, 저장 프로 시저 및 고급 맵핑을 지원해 중복작업을 제거합니다.
- 또 SQL Query문은 한 파일에 구성해서 프로그램 코드와 SQL을 분리해 개발할 수 있는 장점이 있습니다.
- 이렇게 파일에 구성하기 때문에 복잡한 쿼리나 다이내믹한 쿼리에 강하며 단점으로는 비슷한 쿼리가 많아질 수 있는 단점이 있습니다.
JDBC와는 다르게 ResultType, ResultClass 등 VO를 사용하지 않고 결과를 DTO, MAP에 맵핑해 사용할 수 있습니다.
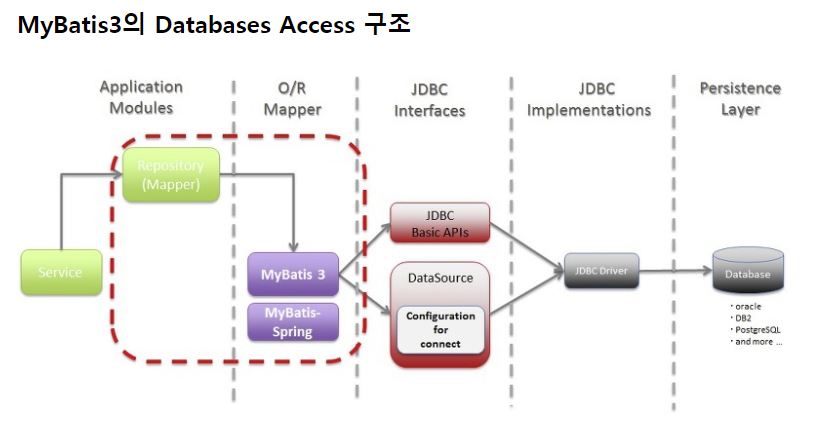
공식 문서는 다음과 같습니다. - https://mybatis.org/mybatis-3/getting-started.html
3. JPA
아래 사진은 NoSQL인 MongoDB를 JPA인 MongoRepository를 활용하기 위해 제가 그렸던 Class Diagram입니다.

사실 간결하게 표현되어 이해하기 어려울 수 있으나 실제 공식문서를 들어가 보면 인터페이스들이 많이 엮여있는 구조로 되어있다는 걸 알 수 있습니다. (비어있는 interface도 존재합니다)
JPA는 위 Mybatis와 JDBC와는 다르게 사용 명세를 많이 참조해야 한다는 단점이 있었습니다.
개인적으로 프로젝트에 적용하기 위해 쿼리문을 작성해보고 이를 함수 명세로 표현하기 위해서 다시 JPA공식문서를 뒤져보는 작업에 시간을 많이 소요했습니다.
이러한 JPA는 익숙해지기에는 시간이 오래 걸렸으나 한번 익숙해진다면 개발 속도는 빨랐기에 저도 가장 많이 사용해보았습니다.
이런 JPA의 특징으로는 ORM 기술 표준의 인터페이스 모음이며 인터페이스이기 때문에 Hibernate, OpenJPA 등이 JPA를 구현합니다.
또 프로젝트의 규모가 커질 경우 속도 저하, 일관성을 무너뜨리는 문제점, 학습 비용이 비싼 점 등이 존재합니다.
추가로 제가 구현할 때 중첩 쿼리문처럼 복잡할 경우에는 @Query 어노테이션으로 직접 Query를 작성할 수 있어 매우 유연한 구현 방식을 제공하고, 팀원들과 협업 시에도 JPA를 이용하기 위한 함수 네이밍 기준이 있어 가독성도 좋았습니다.
코드를 하나씩 다 쳐보며 설명하고 싶으나 시간적인 여유가 없어 현재는 특징 정리 정도로만 하고 추후 재 업데이트를 진행할 예정입니다
Reference
