Spring Web Layer
오늘은 Spring Web Layer에 대해 알아보자.
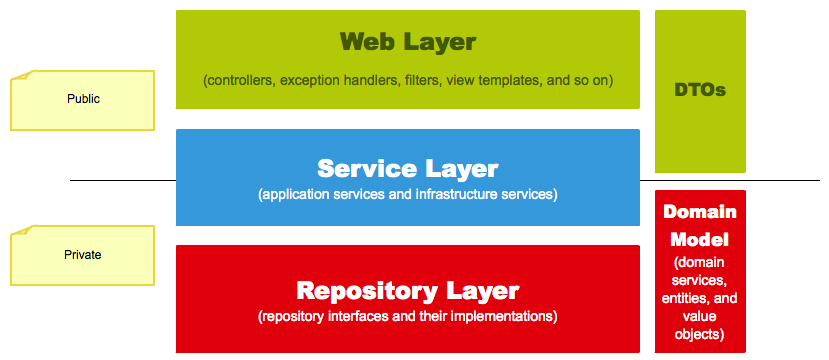
위 사진을 보면 Web, Service, Repository, DTOs, Domain Model이 존재하는데 각 Layer계층 속 controller, service, 등이 포함되어 있고 프로젝트를 구성할 당시 각 레이어에 목적에 맞게 나누어 개발을 진행한다
스프링 웹 아키텍처와 관련하여 아래 레퍼런스 문서를 살펴보면 가장 크게 두가지 원칙을 따르는 것이 기본으로 소개한다.
1. 관심사 분리(SoC(Separation of concerns)) 원칙
- 참고문서 - (https://en.wikipedia.org/wiki/Separation_of_concerns)
- 관심분리라는 원칙을 간단하게 알고넘어가자면 각 부분(클래스 혹은 기능)이 별도의 관심사를 다루도록 컴퓨터 프로그램을 섹션분리하기 위한 설계원칙이다.
- 여기서 관심사란 무엇일까? 를 한번 생각해보자. 관심사는 쉽게 말해 행동이라고 정의하고 이해하면 조금 더 이해하기 쉬웠던 것 같다.
public void First(Object o) { log.info("First Function Call"); System.out.println("My Parameter : " + o.toString()); // Logic ... } public void Second(Object o) { log.info("Second Function Call"); System.out.println("My Parameter : " + o.toString()); //Logic ... }public void printInfo(String functionName, Object o) { log.info("{} Function Call", functionName); System.out.println("My paramter : " + o.toString()); } public void first(Object o) { printInfo("First", o); // Logic ... } public void second(Object o) { printInfo("Second", o); //Logic ... } - 위 코드의 로그와 프린트 부분을 하나의 함수로 바꾸어 구현한다면 다음과 같이 구현할 수 있다.
- 아래 코드를 확인해 보자
위 사항을 조금 더 Spring입장으로 바라본다면 횡단 관심사(Cross-cutting concerns)라고 부르고 이 횡단관심사는 핵심로직이 아닌 위와 같이 로그, 프린트, 파라미터객체, 트랜잭션 등 을 의미한다.
이런 횡단관심사는 다시 또 AOP를 통해 횡단 관심사 분리를 할 수 있으니 AOP에 대한 설명을 한번 더 확인해 보면 좋을 것 같다.
2. KISS(Keep It Simple Stupid) 원칙
참고문서 - (https://en.wikipedia.org/wiki/KISS_principle)
- 키스원칙이라 불리며 KISS는 "Keep it simple, stupid", "keep it short and simple", "keep it short and sweet" 의미이다
- 간단하게 말하자면 코드를 단순하게 만드는 것이 좋고 불필요하게 장황하거나 복잡해지는 것을 피하라는 의미로 이해하면 좋겠다.
본론으로 돌아와서 위 두 가지를 간단하게 요약하자면 한 가지 기능만을 작동하도록 함수를 구현하되 단순하게 코드를 구성하라는 의미가 된다.
이러한 원칙을 따르며 각 레이어에 대한 특징을 살펴보자.
- Web Layer
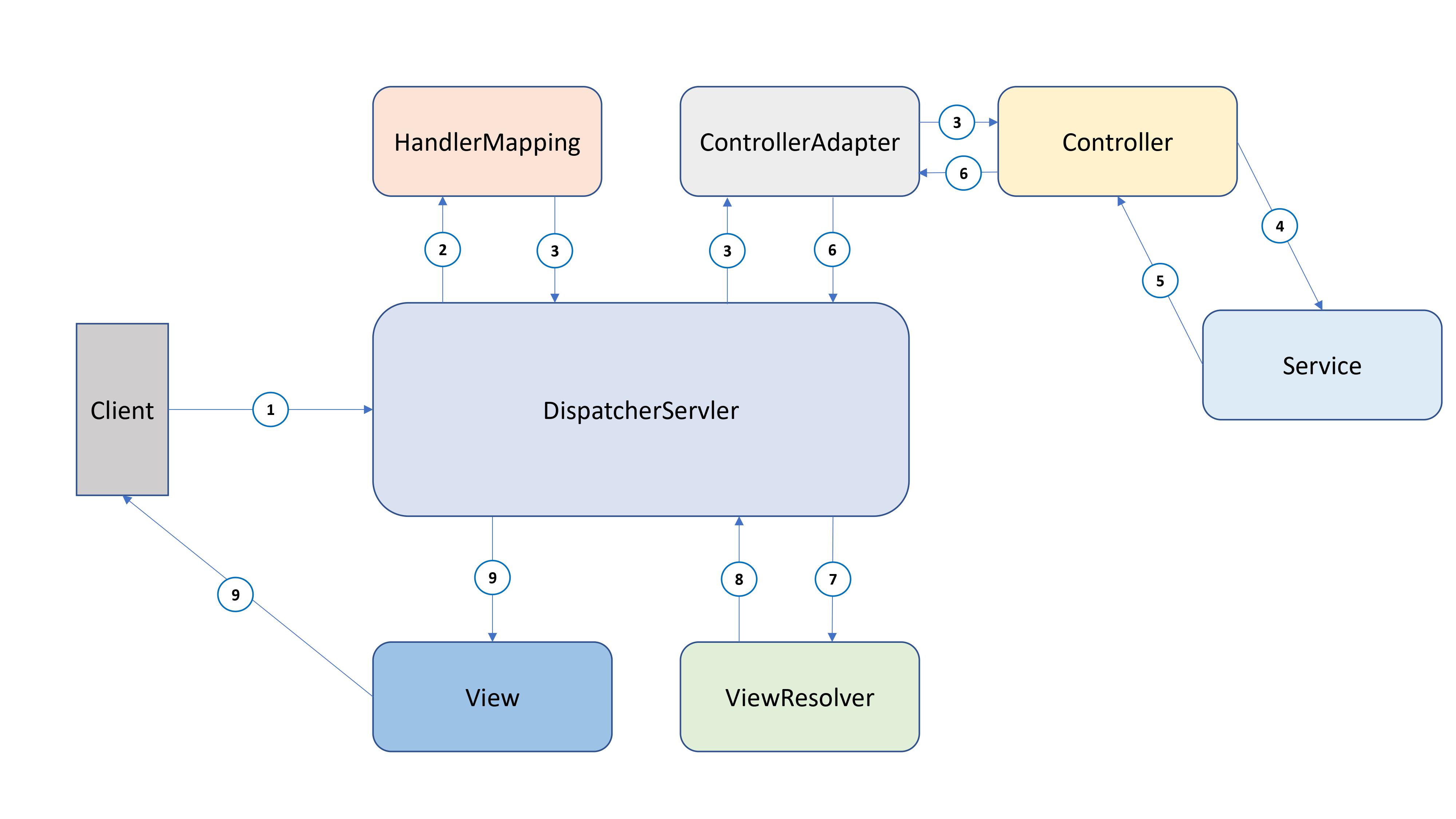
- 가장 앞단으로써 Spring MVC의 동작과정 속 DispatcherServlet처럼 클라이언트의 요청을 가장 처음으로 응답받는 곳이다. 그래서 이 WebLayer가 포함하고 있는 요소들도 Controller를 포함한 예외나필터가 포함되어 있다.
- 또한 클라이언트의 첫 요청이기에 인증 및 권한 관련 부분도 여기에 해당한다.
- Service Layer
- Web Layer보다 아래 속하며, 트랜잭션 경계 역할을 수행한다 또 서비스계층의 공용 API를 제공하고 권한부여등의 기능을 담당한다 쉽게 말해 WebLayer단에서 필요한 작은 기능단위들을 구현되어 있는 Layer라고 생각하면 좋을 것 같다.
- Repository Layer
- 웹 애플리케이션의 최 하위계층으로 사용되는 데이터의 저장소와 통신을 담당합니다 쉽게 말해 데이터베이스와 통신역할을 수행한다.
- DTOs
- DTO들의 집합을 의미한 것이고 DTO(Data Transfer Object)는 데이터 전송을 목적으로 하는 객체다
- 이 객체는 애플리케이션 계층 간 데이터를 전달하는 용으로 사용된다.
- Domain Model
- 도메인 모델은 다시 3가지로 나눌 수 있다
-
- 도메인 서비스
- 도메인 서비스는 쉽게 말해 비즈니스로직이라 말하는 로직적인 관점들이 포함된 작업을 제공하는 비저장 클래스이다.
- 엔티티
- 엔티티는 전체 수명주기동안 변경되지 않고 유지되는 개체이다.
- 개체
- 개체는 속성이나 사물 등을 설명하며 고유 ID나 수명 주기가 없다
- 도메인 서비스
각 레이어 중 웹 레이어는 데이터 전송 개체만 처리해야 하고 서비스계층은 DTO를 매개변수로 사용해야 한다.
또 레포지토리계층은 엔티티를 매개변수로 사용해야 하며 각 계층에서의 구현을 통해 적절한 계층의 요소를 사용하는 것에 익숙해진다면 지금 설명하는 것들이 이해하는데 큰 도움이 될 거라 생각된다.
마지막으로 DTO사용이 필수적인지에 대한 질문에 따른 답변을 확인해 보자
실제로 구현시에 엔티티를 그냥 컨트롤러에서 반환하는 식으로도 구현을 진행할 수 있는데 이러한 DTO가 반드시 사용해야 하는 건지 의문을 가질 수 있다. 실제로 나도 VO와 DTO가 많이 헷갈리기도 했고...
그러나 위 사진을 자세히 보게 된다면 Public, Private으로 표현된 부분이 이 의문에 대한 시원한 답변이라 생각한다.
말 그대로 엔티티, 도메인모델들은 클라이언트입장에서는 감춰지고 보이지 않아야 하며 이 모델들 역시나 클라이언트 친화적으로 생성된 것이 아니기에 DTO를 통해 도메인을 숨기며 맞춤형 DTO로 제공할 수 있다는 점에서 사용한다
그리고 DTO를 변경하지 않는 한 도메인 모델의 변화에도 상관없이 제공될 수 있기에 운영, 유지보수 측면에서 장점이라 생각이 들었다.
오늘은 이것으로 Spring Web Layer에 대하여 알아보았다.
Reference
'Spring, Spring Boot' 카테고리의 다른 글
| Spring MVC 동작과정 (0) | 2023.01.11 |
|---|---|
| SOLID 객체지향 설계의 5가지 원칙 (0) | 2022.05.13 |
| Spring AOP 정리 (0) | 2022.01.01 |
| Spring 어노테이션(Annotation) 정리 (0) | 2021.12.28 |