목차
소개
Java에서는 보통 웹 개발을 진행 시 Log관련된 부분들은 어떤 방식으로 사용할까요?
자바 웹 백엔드개발을 하고 있는 주니어 레벨의 개발자분들은 ( 저 포함 ) 제가 느꼈을 때 라이브러리를 단순 사용하기만 하며 로그 라이브러리를 직접 뜯어보고 응용을 해보신 분들은 없을 거라 생각합니다.
하지만 이러한 로그관련된 라이브러리도 자바에 내장된 로그 기능을 이용해서 개발되었다고 이해할 수 있는데요, 오늘은 이 내부 Log관련된 기능들이 어떤 식으로 정의되고 사용되는지에 대하여 깊이 알아보려고 합니다.
우선 Log4j2에 대한 설명으로 시작하려고 합니다.
Log4j2
- Log4j2 는 자바 로깅 라이브러리입니다. Log4j2 를 설명하기 이전 여러 로깅 라이브러리에 대해 간단하게 소개하고 넘어가겠습니다.
- 자바의 로깅 라이브러리는 다음과 같이 있습니다.
- java.util.logging.Logger
- Log4J, log4j2
- Logback
- SLF4j
자바의 로깅 라이브러리는 다음과같은 시간순으로 개발되었습니다.
- Log4j → Logback → Log4j2 여기서 java.util.logging.Logger는 java언어의 java.util.logging 패키지에 속해있는 로깅용 유틸 클래스입니다.
외부 라이브러리 사용이 필요 없으며 파일이나 콘솔에 로그 내용을 출력할 수 있습니다.
이후 log4j는 가장 오래된 로깅 프레임워크로써 Apache의 Java기반 로깅 프레임 워크입니다.
이런 Log4j는 다음과 같은 구성을 나타내며 구성내의 Appender 부분을 해당 문서에서 Custom하여 적용하는 방법에 대한 설명을 이후 설명드릴 예 정입니다.
| 요소 | 설명 |
|---|---|
| Logger | 출력할 메시지를 Appender에게 전달 |
| Appender | 전달된 로그를 어디에 출력할 것인지 결정(Console, File, JDBC 등) |
| Layout | 로그를 어떤 형식으로 출력할 것인지 결정 |
이런 Log4j 는 다음과같이 사용할 수 있습니다.
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
class Log4jLogger {
private static Logger logger = LogManager.getLogger(Log4jLogger.class);
void method() {
logger.info("info log : {}", 1);
}
}
이러한 Log4j의 버전업이 Log4j2 입니다.
여러 차이점이 존재하지만 그중에서도 큰 차이라고 생각되는 부분은 Sl4j의 지원 여부라고 생각됩니다.
이어서 Appender에 대한 자세한 설명을 이어가겠습니다.
SAS WIKI에서는 Console Appender와 RollingFileAppender, FileAppender에 대한 설명이 나와있지만 그 밖에도 여러 Appender가 존재하며 제가 설정한 방식은 객체를 만들고 적용하였지만 꼭 객체를 만들어야 하는 것은 아닌 걸로 생각됩니다.
Appender는 여러 개가 존재하며 공식문서상 나와있는 부분은 다음과 같습니다. log4j2 공식문서
Appenders :: Apache Log4j
Jakarta EE 8 and all Java EE applications servers use the legacy javax package prefix instead of jakarta. If you are using those application servers, you should replace the dependencies above with: We assume you use log4j-bom for dependency management. org
logging.apache.org

이러한 Appender들 중 이번 글에서는 가장 자주 사용되는 RollingFileAppender에 대한 간단한 설명정도만 하고 넘어가려고 합니다.
이후 필요에 의해 다른 로그가 필요할 경우 appender를 공식문서를 참고하여 작성 및 등록하면 적용시킬 수 있을 거라 생각합니다.
RollingFileAppender는 FileAppender를 상속하여 로그 파일을 rollover 합니다.(File Appender는 단순히 파일에 로그를 쓰는 것이라 생각하시면 됩니다.) 여기서 rollover는 타깃 파일을 바꾸는 것으로 이해할 수 있습니다. 예를 들어, RollingFileAppender가 타깃 파일로 log.txt에 로그 메시지를 append 하다가 어느 지정한 조건에 다다르면, 타깃 파일을 다른 파일로 바꿀 수 있습니다.
ex. 일자별로 로그 파일을 저장하고 싶은 경우, 파일의 크기별로 로그파일을 저장하고 싶은 경우 등등..
RollingFileAppender와 함께 동작하는 두 가지 component가 존재합니다. 첫 번째는 RollingPolicy로 rollover에 필요한 action을 정의합니다. 두 번째는 TriggeringPolicy로 어느 시점에 rollover가 발생할지 정의합니다. 간단히 RollingPolicy는 what, TriggeringPolicy는 when을 담당하고 있다 보시면 될 것 같습니다.
RollingFileAppender를 사용하기 위해서는 RollingPolicy와 TriggeringPolicy가 모두 필수적으로 필요합니다. 하지만, RollingPolicy는 TriggeringPolicy 인터페이스의 구현체로, 하나의 RollingPolicy만 지정하여도 사용 가능합니다.
RollingFileAppender는 아래의 parameter를 갖습니다. 자세한 내용은 공식문서를 참고해 주시면 좋겠습니다.

이 중에서 제가 작성한 코드의 일부분을 통해 설정한 파라미터들을 보여드리겠습니다.
public static void rollingFileAppenderInitialize(CustomFileAppender config) {
ConfigurationBuilder<BuiltConfiguration> builder = ConfigurationBuilderFactory.newConfigurationBuilder();
builder.setStatusLevel(Level.ALL);
builder.setConfigurationName("CustomFileAppenderConfiguration");
// Adding policies and strategy
ComponentBuilder<?> triggeringPolicy = builder.newComponent("Policies")
.addComponent(builder.newComponent("TimeBasedTriggeringPolicy")
.addAttribute("interval", 1)
.addAttribute("modulate", true))
.addComponent(builder.newComponent("SizeBasedTriggeringPolicy")
.addAttribute("size", "10MB"));
AppenderComponentBuilder appenderBuilder = builder.newAppender("CustomFileAppender", "RollingFile")
.addAttribute("fileName", config.setFileName())
.addAttribute("filePattern", config.setFilePattern())
.addAttribute("immediateFlush", true)
.addAttribute("append", true)
.addComponent(triggeringPolicy);
appenderBuilder.add(builder.newLayout("PatternLayout")
.addAttribute("pattern", config.setPattern().getConversionPattern()));
appenderBuilder.addComponent(builder.newComponent("DefaultRolloverStrategy")
.addAttribute("max", "30"));
builder.add(appenderBuilder);
// // Adding logger with filter if available
LoggerComponentBuilder loggerBuilder = builder.newLogger("WriteLogger", config.setLogLevel());
// FilterComponentBuilder filterBuilder = builder.newFilter("RegexFilter", Filter.Result.ACCEPT,
// Filter.Result.DENY)
// .addAttribute("pattern", ".*(error|fail).*");
//
// loggerBuilder.add(filterBuilder);
loggerBuilder.add(builder.newAppenderRef("CustomFileAppender"));
builder.add(loggerBuilder);
// Adding root logger
// builder.add(builder.newRootLogger(config.setLogLevel())
// .add(builder.newAppenderRef("CustomFileAppender")));
Configuration configuration = builder.build();
((LoggerContext) LogManager.getContext(false)).start(configuration);
Configurator.initialize(configuration);
LoggerContext ctx = (LoggerContext) LogManager.getContext(false);
Configurator.setRootLevel(Level.ALL);
// Start the appender manually if necessary
Appender appender = ctx.getConfiguration().getAppender("CustomFileAppender");
if (appender != null) {
appender.start();
}
configuration.addAppender(appender);
configuration.getRootLogger().addAppender(appender, null, null);
// Update the logger context
ctx.updateLoggers();
}해당 이니셜라이즈 메서드에 파라미터로 넘어오는 것은 SAS WIKI에서 설명하고 있는 CustomFileAppender입니다. 해당 객체를 그대로 넘겨주었을 시 다음과 같이 LoggerContext에 Appender를 추가 및 업데이트합니다.
그렇다면 한 가지 의문이 들 수 있을 것 같습니다. 해당 클래스객체를 꼭 안 만들어도 적용시킬 수 있는 것이 아닌가 라는 생각이 들 수 있는데 해당 파라미터의 어팬더를 꼭 안 만들어도 되지만 객체의 구현된 내용 일부만을 조금 수정하는 것이 앞으로 여러 개의 Appender 가 늘어남에 따라 속성값을 관리해야 하는 측면에서는 개발하기 수월해질 것 같습니다.
ex) Message 국제화와 같이 반복사용되는 문자내용의 관리적인 측면이라 생각하셔도 좋을 것 같습니다.
이런 식으로 rollingfileappender에 대한 설명은 넘어가겠습니다.
이어서 Sl4j의 간단한 설명을 진행하겠습니다.
Sl4j
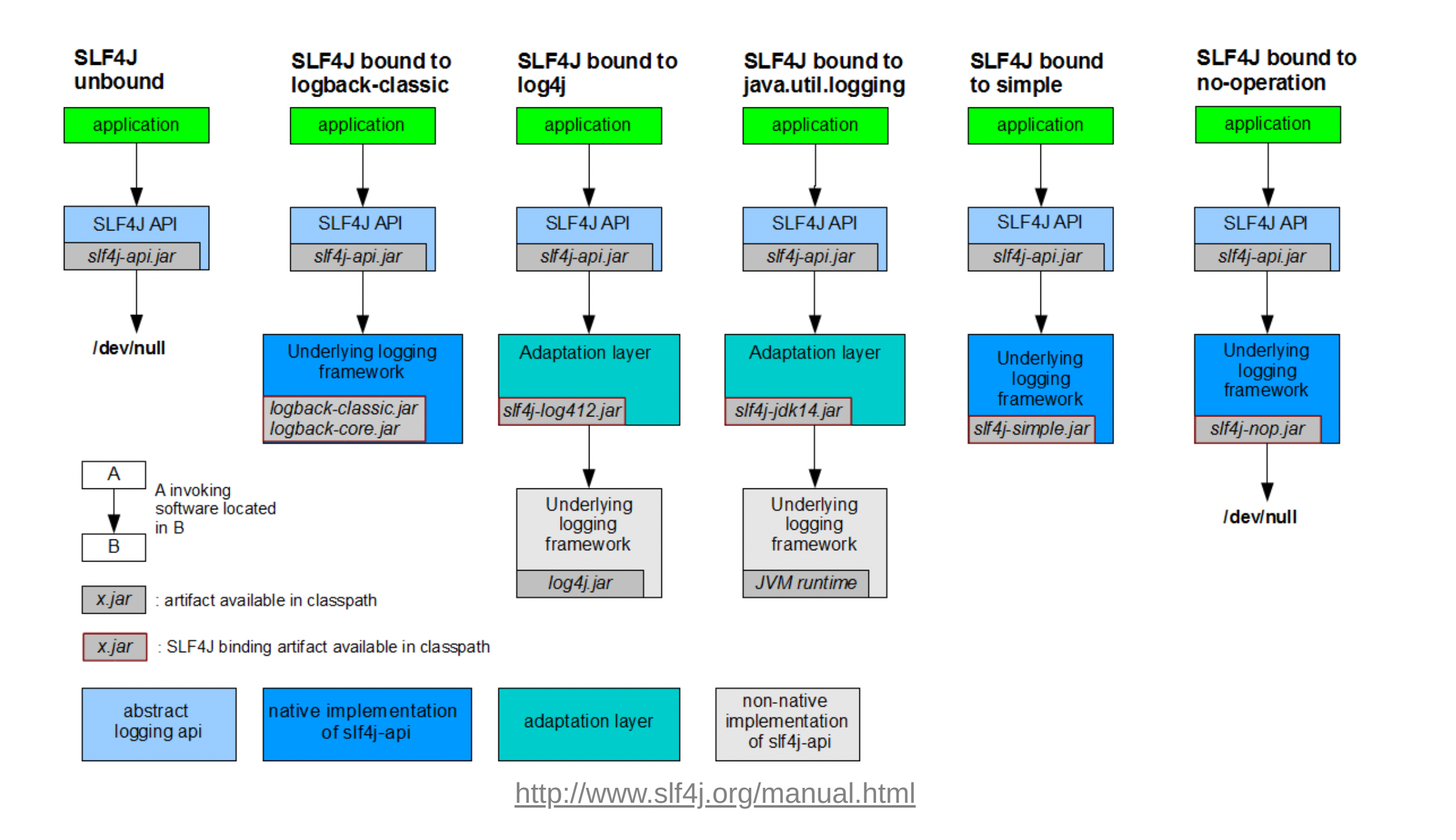
SLF4J(Simple Logging Facade for Java)는 java.util.logging, logback 및 log4j와 같은 다양한 로깅 프레임 워크에 대한 추상화(인터페이스) 역할을 하는 라이브러리입니다.
logger의 추상체로써, 인터페이스 이므로 SLF4j 인터페이스를 사용해서 로깅하게 되면 구현체만 갈아 끼우면 logback이나 log4j 등으로
마이그레이션 할 수 있습니다.
구현체로는 logback, log4j2 등이 있습니다.
디자인 패턴 중 퍼사드패턴처럼 인터페이스만을 제공되게 하여 보다 더 편리하게 사용할 수 있도록 지원되는 라이브러리입니다.
초기의 Spring은 JCL(Jakarta Commons Logging)을 이용하여 로깅하였으나, GC가 제대로 동작하지 않는다는 단점이 있었고
이를 해결하기 위해 도입한 것이 SLF4j이며 JCL의 문제를 해결하기 위해 클래스 로더 대신에 컴파일 시점에 구현체를 선택하도록 하였습니다.
참고 자료
'JAVA' 카테고리의 다른 글
| [JAVA & Database] JDBC, MyBatis, JPA 의 차이점 (1) | 2022.09.26 |
|---|---|
| [Java] 언어의 특징 (2) | 2022.09.09 |
| [JAVA]직렬화 - Serializable란? (0) | 2022.05.16 |
| [JAVA]DAO, DTO, VO 정리. (0) | 2021.12.25 |